Adapting to Unknown Low-Dimensional Structures in Score-Based Diffusion Models
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
![]()

目录
0. 摘要
1. 引言
1.1 扩散模型
1.2 现有结果的不足
1.3 我们的贡献
2. 问题设置
3. 主要结果
3.1 收敛性分析
3.2 系数设计的唯一性
4. 对 DDPM 采样器的分析(定理 1 证明)
5. 讨论
0. 摘要
本文研究基于分数的扩散模型,其目标分布集中于或接近其所在的高维空间中的低维流形,这是自然图像分布的常见特征。尽管先前已有尝试理解扩散模型的数据生成过程,但在存在低维结构的情况下,现有理论支持仍然非常不足。本文增强了这一点。对于流行的去噪扩散概率模型(DDPM),我们发现每个去噪步骤中误差对环境维度 d 的依赖通常是不可避免的。我们进一步识别出一种独特的系数设计,使得收敛速率达到 O(k^2 / √T) 的数量级(最高可达对数因子,up to log factors),其中 k 是目标分布的内在维度,T 是步骤数量。这代表了第一个理论证明,表明 DDPM 采样器能够适应目标分布中未知的低维结构,突显了系数设计的重要性。所有这些都是通过一组新颖的分析工具实现的,这些工具以更确定的方式刻画了算法动态。
1. 引言
基于分数的扩散模型是一类生成模型,因其能够从复杂分布(如图像、音频和文本)中生成高质量的新数据实例而在机器学习和人工智能领域中获得了广泛关注(Dhariwal 和 Nichol,2021;Ho 等,2020;Sohl-Dickstein 等,2015;Song 和 Ermon,2019;Song 等,2021)。这些模型通过逐渐将噪声转化为目标分布的样本来运行,该过程由预训练的神经网络引导,这些神经网络近似得分函数。在实际应用中,得分驱动扩散模型在各个领域生成现实且多样的内容方面表现出了显著的性能,达到了生成式 AI 的最新技术水平(Croitoru 等,2023;Ramesh 等,2022;Rombach 等,2022;Saharia 等,2022)。
1.1 扩散模型
基于分数的扩散模型的发展深深植根于随机过程的理论。在高层次上,我们考虑一个前向过程:
![]()
其中从目标数据分布中抽取一个样本(即 X0∼p_data),然后逐渐将其扩散为高斯噪声。扩散模型的关键在于构造一个反向过程:
![]()
![]()
该过程从纯高斯噪声开始(即 Y_T∼N(0,I_d)),并逐渐将其转化为一个新的样本 Y0,其分布与 p_data 相似。
经典的关于随机微分方程(SDEs)时间反转的结果(Anderson,1982;Haussmann 和 Pardoux,1986)为上述任务提供了理论基础。考虑一个连续时间的扩散过程:
![]()
对于某个函数 β:[0,T]→R^+,其中 (Wt)_(0≤t≤T) 是标准布朗运动。对于广泛的函数 β,这个过程以指数速度收敛到高斯分布。设 p_(Xt) 为 Xt 的密度。可以构造一个反向时间的 SDE:
![]()
其中 (Zt)_(0≤t≤T) 是另一个标准布朗运动。定义 Y_t= ˜ Y_(T−t)。众所周知,对于所有 0≤t≤T,
![]()
这里,∇log p_(Xt) 被称为 Xt 的分布的得分函数,它并不显式已知。
上述结果激发了以下范式:我们可以通过时间离散化扩散过程(1.3)来构建前向过程(1.1),并通过离散化反向时间 SDE(1.4)和从数据中学到的得分函数来构建反向过程(1.2)。这种方法催生了流行的 DDPM 采样器(Ho等,2020;Nichol 和 Dhariwal,2021)。尽管 DDPM 采样器的理念根植于 SDE 理论,但本文中提出的算法和分析不需要任何 SDE 的先验知识。
本文通过建立反向过程输出分布与目标数据分布之间的接近性来检验 DDPM 采样器的准确性。由于在完美得分估计的连续时间极限中,这两个分布是相同的,DDPM 采样器的性能受到两种误差来源的影响:离散化误差(由于有限的步骤数量)和得分估计误差(由于得分估计的不完美)。本文将得分估计步骤视为一个黑箱(通常通过训练大型神经网络来解决),重点研究时间离散化和不完美的得分估计如何影响 DDPM 采样器的准确性。
1.2 现有结果的不足
过去几年中,人们对研究 DDPM 采样器的收敛保证产生了极大的兴趣(Benton等,2023;Chen等,2023a,c;Li等,2024)。为了便于讨论,我们考虑一个理想的设置,即完美得分估计。在这种情况下,现有结果可以解释如下:要达到 ε-精度(即目标分布与输出分布之间的总变差距离(total variation distance)小于ε),需要采取超过 poly(d)/ε^2 数量级的步骤(最高可达对数因素),其中 d 是问题的维度。在这些结果中,最先进的是 Benton 等(2023),其实现了对维度 d 的线性依赖。
然而,DDPM 采样器的实际性能与现有理论之间似乎存在显著差距。例如,对于两个广泛使用的图像数据集,CIFAR-10(维度 d = 32×32×3)和 ImageNet(维度 d ≥ 64 × 64 × 3),已知 50 和 250 步骤(也称为 NFE,函数评估次数)足以生成良好的样本(Dhariwal和Nichol,2021;Nichol和Dhariwal,2021)。这与上述现有理论保证形成鲜明对比,后者建议步骤数量 T 应超过维度 d 的数量级以达到良好性能。
实证证据表明,自然图像的分布集中在它们存在的高维空间中的低维流形上或附近(Pope等,2021;Simoncelli和Olshausen,2001)。鉴于此,一个合理的推测是,DDPM 采样器的收敛速度实际上取决于内在维度而非环境维度。然而,当目标数据分布的支持集具有低维结构时,对扩散模型的理论理解仍然非常欠缺。作为一些最近的尝试,De Bortoli(2022)在Wasserstein-1度量下建立了第一个收敛保证。然而,他们的误差界限对环境维度 d 具有线性依赖,并且对低维流形的直径具有指数依赖。另一个最近的工作(Chen等,2023b)主要关注利用低维结构的适当选择的神经网络进行得分估计,这也不同于我们的主要关注点。
1.3 我们的贡献
鉴于理论与实践之间的巨大差距以及先前结果的不足,本文迈出了理解在目标数据分布具有低维结构时 DDPM 采样器性能的一步。我们的主要贡献可以总结如下:
- 我们表明,通过特定的系数设计,评估 X1 和 Y1 的法则(laws)的总变差距离的 DDPM 采样器的误差上限为:
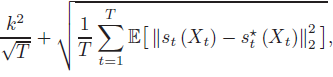
- 该上限最高可达对数因子(logarithmic factors),其中 k 是目标数据分布的内在维度(将稍后严格定义),并且 s*_t(对应于 st)是在每一步的真实(对应于学到的)得分函数。第一项代表离散化误差(随着步骤数 T 趋向无穷大而消失),而第二个项应被解释为得分匹配误差。该界限几乎与维度无关——环境维度 d 仅出现在对数项中。
- 我们还表明,我们选择的系数在某种意义上是独特的调度(schedule),它不会在每一步产生与环境维度 d 成比例的离散化误差。这与没有低维结构的一般设置形成鲜明对比,在一般设置中,相当广泛的系数设计可以导致对 d 具有多项式依赖的收敛速度。此外,这证实了通过精心设计系数可以提高 DDPM 采样器性能的观察结果(Bao等,2022;Nichol和Dhariwal,2021)。 据我们所知,本文提供了第一个理论,证明了 DDPM 采样器在适应未知低维结构方面的能力。
2. 问题设置
在本节中,我们介绍扩散模型和DDPM采样器的一些预备知识和关键成分。
前向过程。我们考虑形式如下的前向过程(1.1):
![]()
![]()
其中,学习率 β_t ∈ (0, 1) 将在稍后指定。对于每个 t >= 1,X_t 在 R^d 上具有概率密度函数(PDF),我们将用 q_t 表示 X_t 的法则(law)或 PDF。设
![]()
可以直接验证,
![]()
我们将选择学习率 βt 以确保 ˉαT 变得极小,使得 q_T ≈ N(0,I_d)。
得分函数。构建 DDPM 采样器的反向过程的关键成分是与每个 qt 相关的得分函数 s*_t:Rd→Rd,定义为
![]()
这些得分函数不是显式已知的。这里我们假设可以访问每个 s*_t(·) 的估计值 st(⋅),并定义平均的 ℓ2 得分估计误差为

此量度捕捉了我们理论中不完美得分估计的影响。
DDPM 采样器。为了构建反向过程(1.2),我们使用 DDPM 采样器:
![]()
![]()
其中,ηt,σt>0 是超参数,在目标数据分布具有低维结构时对 DDPM 采样器的性能起着重要作用。正如我们将看到的,我们的理论建议如下选择:
![]()
对于每个 1≤t≤T,我们将用 pt 表示 Y_t 的 law 或 PDF。
目标数据分布。令 X ⊆ R^d 为目标数据分布 p_data 的支持集,即满足 p_data(C)=1 的最小闭集 C ⊆ R_d。为了最大限度地实现一般性,我们使用 ε-net 和覆盖数(covering number)的概念(参见 Vershynin (2018))来表征 X 的内在维度。对于任意 ϵ>0,如果对于 X 中的任意 x∈X,都存在某个 N_ϵ ⊆ X 中的 x′ 满足
![]()
则称 N_ϵ 是 X 的 ε-net。覆盖数 N_ϵ(X) 定义为 X 的 ε-net 的最小可能基数。
- (低维性)固定 ϵ=T^(−c_ϵ),其中 c_ϵ>0 是某个足够大的通用常数。我们将 X 的内在维度定义为某个量 k>0,使得对于某个常数 C_cover>0,下式成立。
![]()
- (有界支持)假设存在一个通用常数 c_R>0,使得下式成立。也就是说,我们允许 X 的直径随着步骤数 T 以多项式增长。
![]()
我们的设置允许 X 集中在低维流形上或其附近,这比假设精确的低维结构更宽松。作为一个合理的检查,当 X 位于 Rd 的 r-维子空间中时,标准体积论证(standard volume argument)(参见 Vershynin (2018, Section 4.2.1))给出
![]()
![]()
表明在这种情况下内在维度 k 的数量级为 r。
学习率调度(schedule)。按照 Li 等(2024)的方法,我们采用以下学习率调度:
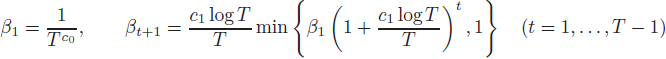
对于某些足够大的常数 c0,c1>0。此安排不是唯一的——任何其他满足引理 8 中性质的 βt 安排都可以在本文中得到相同的结果。
3. 主要结果
我们现在可以提出 DDPM 采样器的主要理论保证。
3.1 收敛性分析
我们首先提出 DDPM 采样器的收敛性理论。证明见第 4 节。
定理 1:假设我们采用 DDPM 采样器(2.3)的系数 ηt = η*_t 和 σt = σ*_t(参见(2.4)),则存在某个通用常数 C>0,使得(全变差距离,total variation)
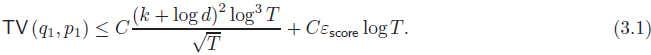
定理 1 带来几个重要的推论。公式 (3.1) 中的两个项分别对应于离散化误差和得分匹配误差。暂时假设得分估计完美(即 ϵ_score=0),我们的误差界限 (3.1) 表示要达到 ϵ 精度的迭代复杂度为 k^4/ϵ^2(最高可达对数因子),对于任何非平凡的目标精度水平 ϵ<1。在不存在低维结构的情况下,即目标数据分布的内在维度 k 渐进等于环境维度(高维空间的维度) d:
![]()
我们的结果也恢复了 Benton 等(2023);Chen 等(2023a,c);Li 等(2024)中阶数为 poly(d)/ϵ^2 的迭代复杂度。这表明,我们的系数选择 (2.4) 使得 DDPM 采样器能够适应目标数据分布中可能存在的(未知的)低维结构,并且在最一般的设置中仍然是一个有效的标准。公式 (3.1) 中的得分匹配误差与 ϵ_score 成正比,这表明 DDPM 采样器对不完美的得分估计具有稳定性。
3.2 系数设计的唯一性
本节中,我们研究了系数设计在 DDPM 采样器适应内在低维结构中的重要性。我们的目标是展示,除非根据 (2.4) 选择 DDPM 采样器 (2.3) 的系数 ηt,否则在每一步去噪过程中都会出现与环境维度 d 成正比的离散化误差。
在本文以及大多数先前的 DDPM 文献中,对误差(全变差距离,total variation) TV(q1,p1) 的分析通常从以下分解开始:
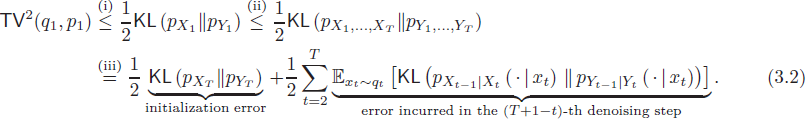
这里步骤 (i) 由 Pinsker 不等式得出,步骤 (ii) 利用数据处理不等式,而步骤 (iii) 使用了 KL 散度的链规则。我们可以将上述分解中的每一项解释为每一步去噪过程中引起的误差。事实上,这个分解也与逆过程负对数似然的变分界限密切相关,这是训练 DDPM 的优化目标(Bao 等,2022;Ho 等,2020;Nichol 和 Dhariwal,2021)。
我们考虑目标分布 p_data=N(0,I_k),其中 I_k∈R^(d×d) 是一个对角矩阵,满足 I_(i,i)=1 对于 1≤i≤k 和 I_(i,i)=0 对于 (k+1)≤i≤d。这是一个在 R^d 上支持在 k 维子空间上的简单分布。我们的第二个理论结果为这种目标分布的每一步去噪过程中引起的误差提供了下界。证明见附录 B。
定理 2:考虑目标分布 p_data=N(0,I_k),假设 k≤d/2。对于具有完美得分估计的 DDPM 采样器(即,st(⋅)=s*_t(⋅) 对所有 t)和任意系数 ηt,σt>0,我们有
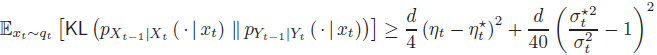
对于每个 2≤t≤T。参见 (2.4) 中 η*_t 和 σ*_t 的定义。
定理 2 表明,除非我们选择 η_t 和 (σ_t)^2 与 η*_t 和 (σ*_t)^2 相同(或极为接近),否则相应的去噪步骤会产生一个与环境维度 d 成线性关系的不期望误差。这凸显了系数设计对于 DDPM 采样器的关键重要性,特别是当目标分布显示低维结构时。
最后,我们要注意上述论点仅展示了系数设计对误差上界 (3.2) 的影响,而不是对误差本身的影响。可能存在更广泛的系数范围可以导致维度无关的误差界限(如 (3.1)),而误差上界 (3.2) 仍然维度相关。这需要新的分析工具(因为我们不能在分析中使用宽松的上界 (3.1)),我们将在未来的工作中讨论。
4. 对 DDPM 采样器的分析(定理 1 证明)
本节致力于建立定理 1。其思想是限制每个去噪步骤中的误差,如在分解(3.2)中描述的那样,即对于每个 2 ≤ t ≤ T,我们需要限制
![]()
这需要连接两个条件分布 p_(X_(t−1)) | Xt 和 p_(Y_(t−1)) | Yt。通过引入辅助随机变量
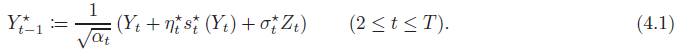
来方便地将时间离散化误差与不完美的评分估计误差分离。
从高层次来看,对于每个 2 ≤ t ≤ T,我们的证明包括以下步骤:
- 确定一个典型集合 At ⊆ Rd × Rd,使得 (Xt,Xt−1) ∈ At 的概率很高。
- 建立点对点的近似
![]()
- 描述由于不完美的评分估计导致的 p_(Y*_(t−1)) | Yt 与 p_(Y_(t−1)) | Yt 的偏差。
5. 讨论
本文研究了当目标分布集中于或接近低维流形时的 DDPM 采样器。我们确定了一种特定的系数设计,使得 DDPM 采样器能够适应未知的低维结构,并建立了一个维度自由(dimension-free)的收敛速率 k^2 / √T(最高可达对数因子)。
我们通过指出几个值得未来研究的方向来总结本文。
- 首先,我们的理论得出的迭代复杂度在内在维度 k 上是四次的,这可能是次优的。改善这种依赖性需要更精细的分析工具。
- 此外,正如我们在第 3.2 节末尾讨论的那样,我们的系数设计(2.4)是否在实现维度无关误差 TV(q1, p1) 方面是唯一的,这一点并不清楚。
- 最后,为 DDPM 采样器开发的分析思想和工具可能被扩展到研究另一种流行的 DDIM 采样器。